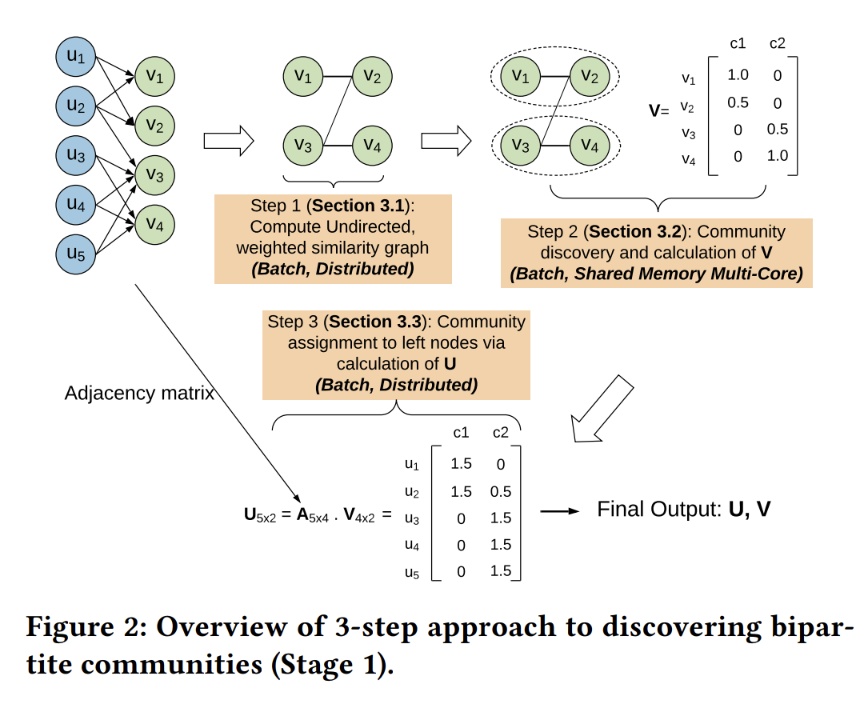
It’s important to know that Twitter has two classes of poster: people over 10K followers, and everyone else. If you’re not an influencer, you might as well be just a tweet. https://www.kdd.org/kdd2020/accepted-papers/view/simclusters-community-based-representations-for-heterogeneous-recommendatio
Basically, the way this works is, if you’re in the top 1% of Twitter users by following count, you’re an influencer. The rest of us users are classified into SimClusters based on which influencers we follow in common. This clustering is done before tweets are delivered to users.
That’s what they mean by a heterogeneous representation: your timeline is literally different than other people’s. You’re trapped in a bubble based on which influencers you follow. This creates the phenomenon known as “ingroup”, among others.
And THAT is why I need 10,000 followers. So I can create a SimCluster of my own, with my cool friends, and we can all hang out together. Including you! Pray for me.
The 10K number is an estimate based on Twitter user counts and the power law followers, but SimClusters are real. There are something like 10,000 of these “communities”, based off clusters discovered in the social graph of the top 1,000,000 users.

This is fine. This is a normal way to find friends on the internet.