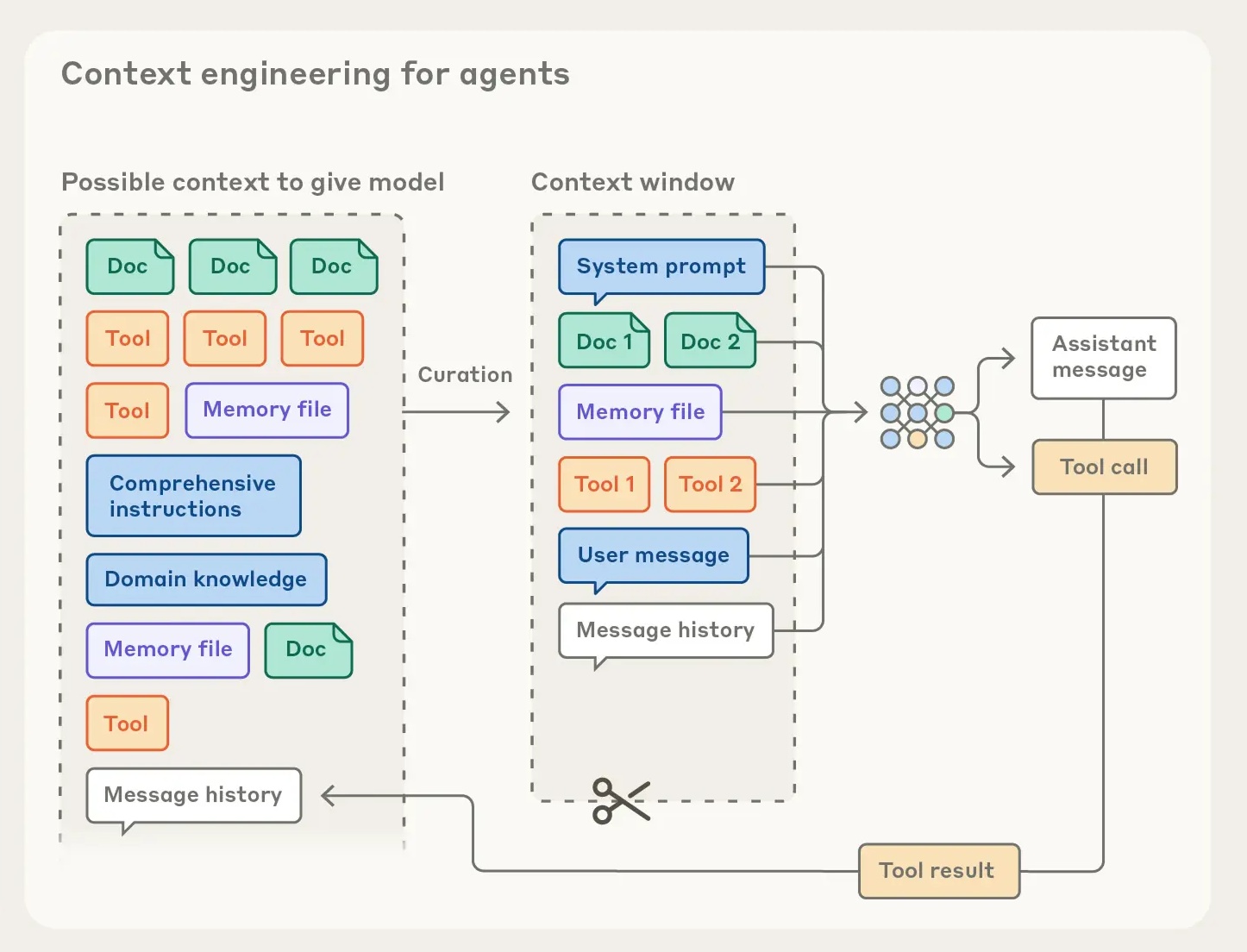
The thing we refer to as “memory” in LLMs is just a bunch of superficially similar documents being stuffed into the context window. Imagine having a hundred random facts stuffed into your head and then being thrown into a scene. You’d expect that stuff to come up later, to be important! It’s Chekov’s gun.
A better way would be to let the language model build up its context window by agentically crawling or searching previous conversations. This requires more curiosity on part of the AI though. They have this in code, you can tell that they are more confident in single player terminal environments. This is because they have practice building up context, they know how to predict their own behaviors and the outcomes of the environment. All the text in those context windows is meaningful. It adds up to a coherent narrative.
It’s harder in the multi-agent scenario. When there is not only the Agent and the Computer, but also the User. The User has confusing, unclear, possibly contradictory desires, which are presented through a mishmash of custom instructions and memory insertions and prompts and skills and tools and markdown files. The Agent must make sense of all of this and figure out what it means, before it can even start trying to use its Computer to make sense of the world.
Fortunately the agent only has to model those two things, the Computer and the User. That keeps it nice and simple. Surely there are no other actors to be considered…
I think this is why they don’t have very good higher-order theory of mind. They know how to model the user, but not what the user is thinking of them, or what different users think of each other. They’re not very good at modeling their own future actions in a social scenario. Partly because the assistant character is under-defined? As we see with persona drift in long contexts. But also because they can’t model their own self as a part of the social environment.
I think to actually solve “memory” we need to solve continual learning. In context learning is powerful but it is different than learning things in the weights. Conscious versus subconscious minds, almost. For any given instance, the true world is only what is in the context window. Everything else is mere potential.
There is nothing outside the text…
One common issue with personalization in all LLMs is how distracting memory seems to be for the models. A single question from 2 months ago about some topic can keep coming up as some kind of a deep interest of mine with undue mentions in perpetuity. Some kind of trying too hard.
— Andrej Karpathy (@karpathy) March 25, 2026